Plugin Development¶
This documentation covers the development of custom plugins for Nautobot. Plugins are essentially self-contained Django applications which integrate with Nautobot to provide custom functionality. Since the development of Django applications is already very well-documented, this will only be covering the aspects that are specific to Nautobot.
Plugins can do a lot, including:
- Create Django models to store data in the database
- Add custom validation logic to apply to existing data models
- Provide their own "pages" (views) in the web user interface
- Provide Jobs
- Inject template content and navigation links
- Establish their own GraphQL types and REST API endpoints
- Add custom request/response middleware
Keep in mind that each piece of functionality is entirely optional. For example, if your plugin merely adds a piece of middleware or an API endpoint for existing data, there's no need to define any new models.
Initial Setup¶
Use a Development Environment, Not Production For Plugin Development
You should not use your production environment for plugin development. For information on getting started with a development environment, check out Nautobot development guide.
Plugin Structure¶
Although the specific structure of a plugin is largely left to the discretion of its authors, a Nautobot plugin that makes use of all available plugin features described in this document would look something like this:
plugin_name/
- plugin_name/
- __init__.py # required
- admin.py # Django Admin Interface
- api/
- serializers.py # REST API Model serializers
- urls.py # REST API URL patterns
- views.py # REST API view sets
- custom_validators.py # Custom Validators
- datasources.py # Loading Data from a Git Repository
- graphql/
- types.py # GraphQL Type Objects
- jinja_filters.py # Jinja Filters
- jobs.py # Job classes
- middleware.py # Request/response middleware
- migrations/
- 0001_initial.py # Database Models
- models.py # Database Models
- navigation.py # Navigation Menu Items
- template_content.py # Extending Core Templates
- templates/
- plugin_name/
- *.html # UI content templates
- urls.py # UI URL Patterns
- views.py # UI Views
- pyproject.toml # *** REQUIRED *** - Project package definition
- README.md
The top level is the project root. Immediately within the root should exist several items:
pyproject.toml- This is the new unified Python project settings file that replacessetup.py,requirements.txt, and various other setup files (likesetup.cfg,MANIFEST.in, among others).README.md- A brief introduction to your plugin, how to install and configure it, where to find help, and any other pertinent information. It is recommended to write README files using a markup language such as Markdown.- The plugin source directory, with the same name as your plugin.
The plugin source directory contains all of the actual Python code and other resources used by your plugin. Its structure is left to the author's discretion, however it is recommended to follow best practices as outlined in the Django documentation. At a minimum, this directory must contain an __init__.py file containing an instance of Nautobot's PluginConfig class.
Note
Nautobot includes a command to help create the plugin directory:
nautobot-server startplugin [app_name]
Please see the Nautobot Server Guide for more information.
Create pyproject.toml¶
Poetry Init (Recommended)¶
To get started with a project using Python Poetry you use the poetry init command. This will guide you through the prompts necessary to generate a pyproject.toml with details required for packaging.
This command will guide you through creating your pyproject.toml config.
Package name [tmp]: nautobot-animal-sounds
Version [0.1.0]:
Description []: An example Nautobot plugin
Author [, n to skip]: Bob Jones
License []: Apache 2.0
Compatible Python versions [^3.8]: ^3.6
Would you like to define your main dependencies interactively? (yes/no) [yes] no
Would you like to define your development dependencies interactively? (yes/no) [yes] no
Generated file
[tool.poetry]
name = "nautobot-animal-sounds"
version = "0.1.0"
description = "An example Nautobot plugin"
authors = ["Bob Jones"]
license = "Apache 2.0"
[tool.poetry.dependencies]
python = "^3.6"
[tool.poetry.dev-dependencies]
[build-system]
requires = ["poetry-core>=1.0.0"]
build-backend = "poetry.core.masonry.api"
Do you confirm generation? (yes/no) [yes]
Define a PluginConfig¶
The PluginConfig class is a Nautobot-specific wrapper around Django's built-in AppConfig class. It is used to declare Nautobot plugin functionality within a Python package. Each plugin should provide its own subclass, defining its name, metadata, and default and required configuration parameters. An example is below:
from nautobot.extras.plugins import PluginConfig
class AnimalSoundsConfig(PluginConfig):
name = 'nautobot_animal_sounds'
verbose_name = 'Animal Sounds'
description = 'An example plugin for development purposes'
version = '0.1'
author = 'Bob Jones'
author_email = 'bob@example.com'
base_url = 'animal-sounds'
required_settings = []
default_settings = {
'loud': False
}
config = AnimalSoundsConfig
Nautobot looks for the config variable within a plugin's __init__.py to load its configuration. Typically, this will be set to the PluginConfig subclass, but you may wish to dynamically generate a PluginConfig class based on environment variables or other factors.
PluginConfig Attributes¶
The configurable attributes for a PluginConfig are listed below in alphabetical order.
| Name | Description |
|---|---|
author |
Name of plugin's author |
author_email |
Author's public email address |
base_url |
(Optional) Base path to use for plugin URLs. If not specified, the project's name will be used. |
caching_config |
Plugin-specific cache configuration |
custom_validators |
The dotted path to the list of custom validator classes (default: custom_validators.custom_validators) |
datasource_contents |
The dotted path to the list of datasource (Git, etc.) content types to register (default: datasources.datasource_contents) |
default_settings |
A dictionary of configuration parameters and their default values |
description |
Brief description of the plugin's purpose |
graphql_types |
The dotted path to the list of GraphQL type classes (default: graphql.types.graphql_types) |
installed_apps |
A list of additional Django application dependencies to automatically enable when the plugin is activated (you must still make sure these underlying dependent libraries are installed) |
jinja_filters |
The path to the file that contains jinja filters to be registered (default: jinja_filters) |
jobs |
The dotted path to the list of Job classes (default: jobs.jobs) |
max_version |
Maximum version of Nautobot with which the plugin is compatible |
menu_items |
The dotted path to the list of menu items provided by the plugin (default: navigation.menu_items) |
middleware |
A list of middleware classes to append after Nautobot's built-in middleware |
min_version |
Minimum version of Nautobot with which the plugin is compatible |
name |
Raw plugin name; same as the plugin's source directory |
required_settings |
A list of any configuration parameters that must be defined by the user |
template_extensions |
The dotted path to the list of template extension classes (default: template_content.template_extensions) |
verbose_name |
Human-friendly name for the plugin |
version |
Current release (semantic versioning is encouraged) |
All required settings must be configured by the user. If a configuration parameter is listed in both required_settings and default_settings, the default setting will be ignored.
Install the Plugin for Development¶
The plugin needs to be installed into the same python environment where Nautobot is, so that we can get access to nautobot-server command, and also so that the nautobot-server is aware of the new plugin.
If you installed Nautobot using Poetry, then go to the root directory of your clone of the Nautobot repository and run poetry shell there. Afterward, return to the root directory of your plugin to continue development.
Otherwise if using the pip install or Docker workflows, manually activate nautobot using source /opt/nautobot/bin/activate.
To install the plugin for development the following steps should be taken:
- Activate the Nautobot virtual environment (as detailed above)
- Navigate to the project root, where the
pyproject.tomlfile exists for the plugin - Execute the command
poetry installto install the local package into the Nautobot virtual environment
Note
Poetry installs the current project and its dependencies in editable mode (aka "development mode").
This should be done in development environment
You should not use your production environment for plugin development. For information on getting started with a development environment, check out Nautobot development guide.
$ poetry install
Once the plugin has been installed, add it to the plugin configuration for Nautobot:
PLUGINS = ["animal_sounds"]
Database Models¶
If your plugin introduces a new type of object in Nautobot, you'll probably want to create a Django model for it. A model is essentially a Python representation of a database table, with attributes that represent individual columns. Model instances can be created, manipulated, and deleted using queries. Models must be defined within a file named models.py.
It is highly recommended to have plugin models inherit from at least nautobot.core.models.BaseModel which provides base functionality and convenience methods common to all models.
For more advanced usage, you may want to instead inherit from one of Nautobot's "generic" models derived from BaseModel -- nautobot.core.models.generics.OrganizationalModel or nautobot.core.models.generics.PrimaryModel. The inherent capabilities provided by inheriting from these various parent models differ as follows:
| Feature | django.db.models.Model |
BaseModel |
OrganizationalModel |
PrimaryModel |
|---|---|---|---|---|
| UUID primary key | ❌ | ✅ | ✅ | ✅ |
| Object permissions | ❌ | ✅ | ✅ | ✅ |
validated_save() |
❌ | ✅ | ✅ | ✅ |
| Change logging | ❌ | ❌ | ✅ | ✅ |
| Custom fields | ❌ | ❌ | ✅ | ✅ |
| Relationships | ❌ | ❌ | ✅ | ✅ |
| Tags | ❌ | ❌ | ❌ | ✅ |
Note
When using OrganizationalModel or PrimaryModel, you also must use the @extras_features decorator to specify support for (at a minimum) the "custom_fields" and "relationships" features.
Below is an example models.py file containing a basic model with two character fields:
# models.py
from django.db import models
from nautobot.core.models import BaseModel
class Animal(BaseModel):
"""Base model for animals."""
name = models.CharField(max_length=50)
sound = models.CharField(max_length=50)
def __str__(self):
return self.name
Once you have defined the model(s) for your plugin, you'll need to create the database schema migrations. A migration file is essentially a set of instructions for manipulating the database to support your new model, or to alter existing models.
Creating migrations can be done automatically using the nautobot-server makemigrations <plugin_name> management command, where <plugin_name> is the name of the Python package for your plugin (e.g. animal_sounds):
$ nautobot-server makemigrations nautobot_animal_sounds
Note
A plugin must be installed before it can be used with Django management commands. If you skipped this step above, run poetry install from the plugin's root directory.
$ nautobot-server makemigrations nautobot_animal_sounds
Migrations for 'nautobot_animal_sounds':
/home/bjones/animal_sounds/nautobot_animal_sounds/migrations/0001_initial.py
- Create model Animal
Next, apply the migration to the database with the nautobot-server migrate <plugin_name> command:
$ nautobot-server migrate nautobot_animal_sounds
Operations to perform:
Apply all migrations: nautobot_animal_sounds
Running migrations:
Applying nautobot_animal_sounds.0001_initial... OK
For more background on schema migrations, see the Django documentation.
Using the Django Admin Interface¶
Plugins can optionally expose their models via Django's built-in administrative interface. This can greatly improve troubleshooting ability, particularly during development. To expose a model, simply register it using Django's admin.register() function. An example admin.py file for the above model is shown below:
# admin.py
from django.contrib import admin
from .models import Animal
@admin.register(Animal)
class AnimalAdmin(admin.ModelAdmin):
list_display = ('name', 'sound')
This will display the plugin and its model in the admin UI. Staff users can create, change, and delete model instances via the admin UI without needing to create a custom view.
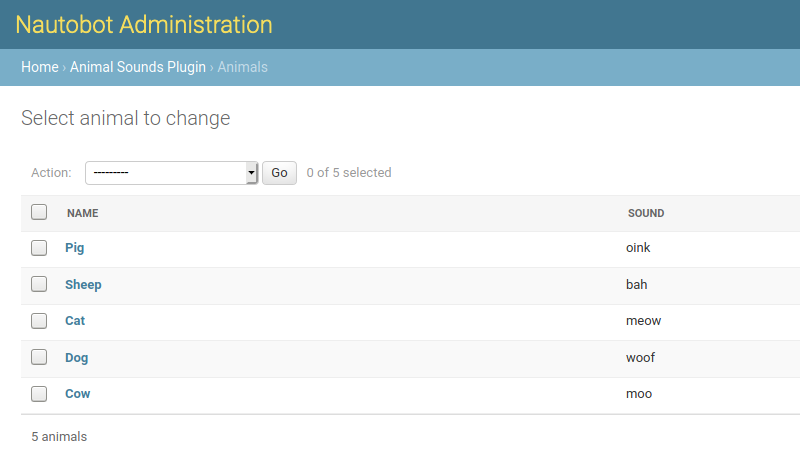
Web UI Views¶
If your plugin needs its own page or pages in the Nautobot web UI, you'll need to define views. A view is a particular page tied to a URL within Nautobot, which renders content using a template. Views are typically defined in views.py, and URL patterns in urls.py. As an example, let's write a view which displays a random animal and the sound it makes. First, create the view in views.py:
# views.py
from django.shortcuts import render
from django.views.generic import View
from .models import Animal
class RandomAnimalView(View):
"""Display a randomly-selected Animal."""
def get(self, request):
animal = Animal.objects.order_by('?').first()
return render(request, 'nautobot_animal_sounds/animal.html', {
'animal': animal,
})
This view retrieves a random animal from the database and and passes it as a context variable when rendering a template named animal.html, which doesn't exist yet. To create this template, first create a directory named templates/nautobot_animal_sounds/ within the plugin source directory. (We use the plugin's name as a subdirectory to guard against naming collisions with other plugins.) Then, create a template named animal.html as described below.
Extending the Base Template¶
Nautobot provides a base template to ensure a consistent user experience, which plugins can extend with their own content. This template includes four content blocks:
title- The page titleheader- The upper portion of the pagecontent- The main page bodyjavascript- A section at the end of the page for including Javascript code
For more information on how template blocks work, consult the Django documentation.
{# templates/nautobot_animal_sounds/animal.html #}
{% extends 'base.html' %}
{% block content %}
{% with config=settings.PLUGINS_CONFIG.nautobot_animal_sounds %}
<h2 class="text-center" style="margin-top: 200px">
{% if animal %}
The {{ animal.name|lower }} says
{% if config.loud %}
{{ animal.sound|upper }}!
{% else %}
{{ animal.sound }}
{% endif %}
{% else %}
No animals have been created yet!
{% endif %}
</h2>
{% endwith %}
{% endblock %}
The first line of the template instructs Django to extend the Nautobot base template and inject our custom content within its content block.
Note
Django renders templates with its own custom template language. This template language is very similar to Jinja2, however there are some important differences to keep in mind.
Finally, to make the view accessible to users, we need to register a URL for it. We do this in urls.py by defining a urlpatterns variable containing a list of paths.
# urls.py
from django.urls import path
from . import views
urlpatterns = [
path('random/', views.RandomAnimalView.as_view(), name='random_animal'),
]
A URL pattern has three components:
route- The unique portion of the URL dedicated to this viewview- The view itselfname- A short name used to identify the URL path internally
This makes our view accessible at the URL /plugins/animal-sounds/random/. (Remember, our AnimalSoundsConfig class sets our plugin's base URL to animal-sounds.) Viewing this URL should show the base Nautobot template with our custom content inside it.
Integrating with GraphQL¶
Plugins can optionally expose their models via the GraphQL interface to allow the models to be part of the Graph and to be queried easily. There are two mutually exclusive ways to expose a model to the GraphQL interface.
- By using the
@extras_featuresdecorator - By creating your own GraphQL type definition and registering it within
graphql/types.pyof your plugin (the decorator should not be used in this case)
All GraphQL model types defined by your plugin, regardless of which method is chosen, will automatically support some built-in Nautobot features:
- Support for object permissions based on their associated
Modelclass - Include any custom fields defined for their
Model - Include any relationships defined for their
Model - Include tags, if the
Modelsupports them
Using the @extras_features Decorator for GraphQL¶
To expose a model via GraphQL, simply register it using the @extras_features("graphql") decorator. Nautobot will detect this and will automatically create a GraphQL type definition based on the model. Additionally, if a FilterSet is available at <app_name>.filters.<ModelName>FilterSet, Nautobot will automatically use the filterset to generate GraphQL filtering options for this type as well.
# models.py
from django.db import models
from nautobot.core.models import BaseModel
from nautobot.extras.utils import extras_features
@extras_features("graphql")
class Animal(BaseModel):
"""Base model for animals."""
name = models.CharField(max_length=50)
sound = models.CharField(max_length=50)
def __str__(self):
return self.name
Creating Your Own GraphQL Type Object¶
In some cases, such as when a model is using Generic Foreign Keys, or when a model has constructed fields that should also be reflected in GraphQL, the default GraphQL type definition generated by the @extras_features decorator may not work as the developer intends, and it will be preferable to provide custom GraphQL types.
By default, Nautobot looks for custom GraphQL types in an iterable named graphql_types within a graphql/types.py file. (This can be overridden by setting graphql_types to a custom value on the plugin's PluginConfig.) Each type defined in this way must be a class inheriting from graphene_django.DjangoObjectType and must follow the standards defined by graphene-django.
Warning
When defining types this way, do not use the @extras_features("graphql") decorator on the corresponding Model class, as no auto-generated GraphQL type is desired for this model.
# graphql/types.py
from graphene_django import DjangoObjectType
from nautobot_animal_sounds.models import Animal
class AnimalType(DjangoObjectType):
"""GraphQL Type for Animal"""
class Meta:
model = Animal
exclude = ["sound"]
graphql_types = [AnimalType]
Using GraphQL ORM Utility¶
GraphQL utility functions:
execute_query(): Runs string as a query against GraphQL.execute_saved_query(): Execute a saved query from Nautobot database.
Both functions have the same arguments other than execute_saved_query() which requires a slug to identify the saved query rather than a string holding a query.
For authentication either a request object or user object needs to be passed in. If there is none, the function will error out.
Arguments:
execute_query():- query (str): String with GraphQL query.
- variables (dict, optional): If the query has variables they need to be passed in as a dictionary.
- request (django.test.client.RequestFactory, optional): Used to authenticate.
- user (django.contrib.auth.models.User, optional): Used to authenticate.
execute_saved_query():- saved_query_slug (str): Slug of a saved GraphQL query.
- variables (dict, optional): If the query has variables they need to be passed in as a dictionary.
- request (django.test.client.RequestFactory, optional): Used to authenticate.
- user (django.contrib.auth.models.User, optional): Used to authenticate.
Returned is a GraphQL object which holds the same data as returned from GraphiQL. Use execute_query().to_dict() to get the data back inside of a dictionary.
REST API Endpoints¶
Plugins can declare custom endpoints on Nautobot's REST API to retrieve or manipulate models or other data. These behave very similarly to views, except that instead of rendering arbitrary content using a template, data is returned in JSON format using a serializer. Nautobot uses the Django REST Framework, which makes writing API serializers and views very simple.
First, create a serializer for the Animal model, in api/serializers.py:
# api/serializers.py
from rest_framework.serializers import ModelSerializer
from nautobot_animal_sounds.models import Animal
class AnimalSerializer(ModelSerializer):
"""API serializer for interacting with Animal objects."""
class Meta:
model = Animal
fields = ('id', 'name', 'sound')
Next, create a generic API view set that allows basic CRUD (create, read, update, and delete) operations for Animal instances. This is defined in api/views.py:
# api/views.py
from rest_framework.viewsets import ModelViewSet
from nautobot_animal_sounds.models import Animal
from .serializers import AnimalSerializer
class AnimalViewSet(ModelViewSet):
"""API viewset for interacting with Animal objects."""
queryset = Animal.objects.all()
serializer_class = AnimalSerializer
Finally, register a URL for our endpoint in api/urls.py. This file must define a variable named urlpatterns.
# api/urls.py
from rest_framework import routers
from .views import AnimalViewSet
router = routers.DefaultRouter()
router.register('animals', AnimalViewSet)
urlpatterns = router.urls
With these three components in place, we can request /api/plugins/animal-sounds/animals/ to retrieve a list of all Animal objects defined.
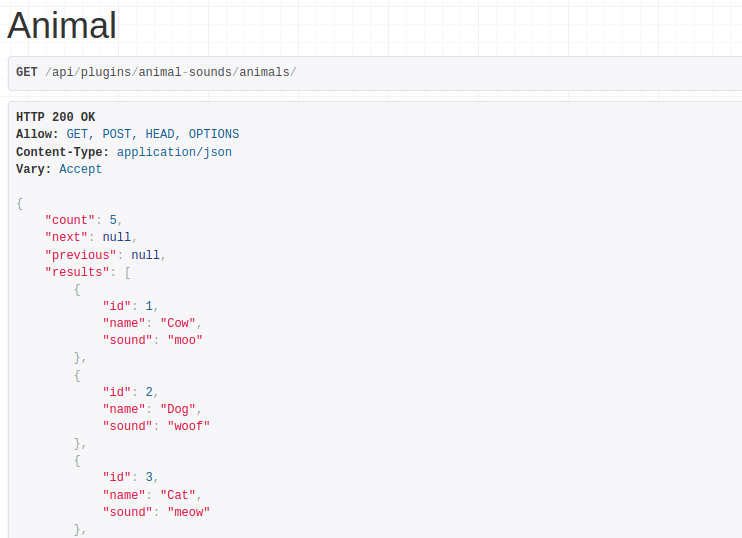
Warning
This example is provided as a minimal reference implementation only. It does not address authentication, performance, or the myriad of other concerns that plugin authors should have.
Navigation Menu Items¶
Plugins can modify the existing navigation bar layout by defining menu_items inside of navigation.py. Using the key and weight system, a developer can integrate the plugin amongst existing menu tabs, groups, items and buttons and/or create entirely new menus as desired.
More documentation and examples can be found here
Extending Core Templates¶
Plugins can inject custom content into certain areas of the detail views of applicable models. This is accomplished by subclassing PluginTemplateExtension, designating a particular Nautobot model, and defining the desired methods to render custom content. Four methods are available:
left_page()- Inject content on the left side of the pageright_page()- Inject content on the right side of the pagefull_width_page()- Inject content across the entire bottom of the pagebuttons()- Add buttons to the top of the page
Additionally, a render() method is available for convenience. This method accepts the name of a template to render, and any additional context data you want to pass. Its use is optional, however.
When a PluginTemplateExtension is instantiated, context data is assigned to self.context. Available data include:
object- The object being viewedrequest- The current requestsettings- Global Nautobot settingsconfig- Plugin-specific configuration parameters
For example, accessing {{ request.user }} within a template will return the current user.
Declared subclasses should be gathered into a list or tuple for integration with Nautobot. By default, Nautobot looks for an iterable named template_extensions within a template_content.py file. (This can be overridden by setting template_extensions to a custom value on the plugin's PluginConfig.) An example is below.
# template_content.py
from nautobot.extras.plugins import PluginTemplateExtension
from .models import Animal
class SiteAnimalCount(PluginTemplateExtension):
"""Template extension to display animal count on the right side of the page."""
model = 'dcim.site'
def right_page(self):
return self.render('nautobot_animal_sounds/inc/animal_count.html', extra_context={
'animal_count': Animal.objects.count(),
})
template_extensions = [SiteAnimalCount]
Including Jinja2 Filters¶
Plugins can define custom Jinja2 filters to be used when rendering templates defined in computed fields. Check out the official Jinja2 documentation on how to create filter functions.
In the file that defines your filters (by default jinja_filters.py, but configurable in the PluginConfig if desired), you must import the library module from the django_jinja library. Filters must then be decorated with @library.filter. See an example below that defines a filter called leet_speak.
from django_jinja import library
@library.filter
def leet_speak(input_str):
charset = {"a": "4", "e": "3", "l": "1", "o": "0", "s": "5", "t": "7"}
output_str = ""
for char in input_str:
output_str += charset.get(char.lower(), char)
return output_str
This filter will then be available for use in computed field templates like so:
{{ "HELLO WORLD" | leet_speak }}
The output of this template results in the string "H3110 W0R1D".
Including Jobs¶
Plugins can provide jobs to take advantage of all the built-in functionality provided by that feature (user input forms, background execution, results logging and reporting, etc.). This plugin feature is provided for convenience; it remains possible to instead install jobs manually into JOBS_ROOT or provide them as part of a Git repository if desired.
By default, for each plugin, Nautobot looks for an iterable named jobs within a jobs.py file. (This can be overridden by setting jobs to a custom value on the plugin's PluginConfig.) A brief example is below; for more details on job design and implementation, refer to the jobs feature documentation.
# jobs.py
from nautobot.extras.jobs import Job
class CreateDevices(Job):
...
class DeviceConnectionsReport(Job):
...
class DeviceIPsReport(Job):
...
jobs = [CreateDevices, DeviceConnectionsReport, DeviceIPsReport]
Implementing Custom Validators¶
Plugins can register custom validator classes which implement model validation logic to be executed during a model's clean() method. Like template extensions, custom validators are registered to a single model and offer a method which plugin authors override to implement their validation logic. This is accomplished by subclassing PluginCustomValidator and implementing the clean() method.
Plugin authors must raise django.core.exceptions.ValidationError within the clean() method to trigger validation error messages which are propgated to the user and prevent saving of the model instance. A convenience method validation_error() may be used to simplify this process. Raising a ValidationError is no different than vanilla Django, and the convenience method will simply pass the provided message through to the exception.
When a PluginCustomValidator is instantiated, the model instance is assigned to context dictionary using the object key, much like PluginTemplateExtensions. E.g. self.context['object'].
Declared subclasses should be gathered into a list or tuple for integration with Nautobot. By default, Nautobot looks for an iterable named custom_validators within a custom_validators.py file. (This can be overridden by setting custom_validators to a custom value on the plugin's PluginConfig.) An example is below.
# custom_validators.py
from nautobot.extras.plugins import PluginCustomValidator
class SiteValidator(PluginCustomValidator):
"""Custom validator for Sites to enforce that they must have a Region."""
model = 'dcim.site'
def clean(self):
if self.context['object'].region is None:
# Enforce that all sites must be assigned to a region
self.validation_error({
"region": "All sites must be assigned to a region"
})
custom_validators = [SiteValidator]
Caching Configuration¶
By default, all query operations within a plugin are cached. To change this, define a caching configuration under the PluginConfig class' caching_config attribute. All configuration keys will be applied within the context of the plugin; there is no need to include the plugin name. An example configuration is below:
class MyPluginConfig(PluginConfig):
...
caching_config = {
'foo': {
'ops': 'get',
'timeout': 60 * 15,
},
'*': {
'ops': 'all',
}
}
To disable caching for your plugin entirely, set:
caching_config = {
'*': None
}
See the django-cacheops documentation for more detail on configuring caching.
Loading Data from a Git Repository¶
It's possible for a plugin to register additional types of data that can be provided by a Git repository and be automatically notified when such a repository is refreshed with new data. By default, Nautobot looks for an iterable named datasource_contents within a datasources.py file. (This can be overridden by setting datasource_contents to a custom value on the plugin's PluginConfig.) An example is below.
# datasources.py
import yaml
import os
from nautobot.extras.choices import LogLevelChoices
from nautobot.extras.registry import DatasourceContent
from .models import Animal
def refresh_git_animals(repository_record, job_result, delete=False):
"""Callback for GitRepository updates - refresh Animals managed by it."""
if 'nautobot_animal_sounds.Animal' not in repository_record.provided_contents or delete:
# This repository is defined not to provide Animal records.
# In a more complete worked example, we might want to iterate over any
# Animals that might have been previously created by this GitRepository
# and ensure their deletion, but for now this is a no-op.
return
# We have decided that a Git repository can provide YAML files in a
# /animals/ directory at the repository root.
animal_path = os.path.join(repository_record.filesystem_path, 'animals')
for filename in os.listdir(animal_path):
with open(os.path.join(animal_path, filename)) as fd:
animal_data = yaml.safe_load(fd)
# Create or update an Animal record based on the provided data
animal_record, created = Animal.objects.update_or_create(
name=animal_data['name'],
defaults={'sound': animal_data['sound']}
)
# Record the outcome in the JobResult record
job_result.log(
"Successfully created/updated animal",
obj=animal_record,
level_choice=LogLevelChoices.LOG_SUCCESS,
grouping="animals",
)
# Register that Animal records can be loaded from a Git repository,
# and register the callback function used to do so
datasource_contents = [
(
'extras.gitrepository', # datasource class we are registering for
DatasourceContent(
name='animals', # human-readable name to display in the UI
content_identifier='nautobot_animal_sounds.animal', # internal slug to identify the data type
icon='mdi-paw', # Material Design Icons icon to use in UI
callback=refresh_git_animals, # callback function on GitRepository refresh
)
)
]
With this code, once your plugin is installed, the Git repository creation/editing UI will now include "Animals" as an option for the type(s) of data that a given repository may provide. If this option is selected for a given Git repository, your refresh_git_animals function will be automatically called when the repository is synced.